












Aujourd’hui à l’occasion de la GTC, NVIDIA a présenté son nouveau GPU à destination du monde professionnel. En effet, le GPU NVIDIA H100 (architecture Hopper) utilise pas moins de 80 000 millions de transistors grâce à TSMC et son procédé de gravure en 4 nm (N4). Ce monstre propose pas moins de 18 432 cœurs CUDA, utilise 80 Go de mémoire de type HBM3 et dispose d’une bande passante colossale de 3 To/s. En comparaison, sur le secteur mainstream avec la RTX 3090 Ti, nous sommes enthousiastes à l’idée que ce soit la première à dépasser les 1000 Mo/s (1008 Mo/s pour être précis). Mais cela représente aussi un gain de +50% par rapport au GPU NVIDIA A100.
NVIDIA présente le GPU H100 : un monstre de puissance et de démesure
En termes de performances, il est question de 60 TFLOP FP64/FP32, 1 000 TFLOP TF32 et 2 000 TFLOP FP16, soit trois fois les performances du précédent GPU NVIDIA A100. En ce qui concerne les performances du FP8, il faut multiplier le tout par 6 et atteint les 4 000 TFLOP. Avec de tels chiffres, il n’est pas étonnant de voir l’utilisation de l’interface PCIe 5.0 pour profiter de la bande passante de 128 Go/s au lieu de 64 Go sur le PCIe 4.0. De même, la 4e génération de la technologie d’interconnexion NVLink offre une bande passante de 900 Go/s (+50%).

En termes de consommation en revanche, les chiffres sont aussi en hausse. En effet, NVIDIA annonce un TDP de 700W pour la version SXM5 et 350W pour la version PCie, soit presque le double comparativement aux 400W du précédent GPU NVIDIA A100 SXM4 qui utilisait aussi 80 Go de mémoire, mais de type HBM2e. Concrètement, la consommation d’énergie augmente de 75% en échange d’une amélioration des performances entre 300 – 600% et 50% en bande passante.
L’architecture GPU NVIDIA Hopper dévoilée aujourd’hui au GTC accélérera la programmation dynamique jusqu’à 40 fois grâce aux nouvelles instructions DPX. Il s’agit d’une technique de résolution de problèmes utilisée dans les algorithmes pour la génomique, l’informatique quantique, l’optimisation des itinéraires et plus encore.
Un jeu d’instructions DPX intégré aux GPU NVIDIA H100 aidera les développeurs à écrire du code pour accélérer les algorithmes de programmation dynamique dans plusieurs secteurs en stimulant les flux de travail pour le diagnostic des maladies, la simulation quantique, l’analyse des graphes oui encore l’optimisation du routage.
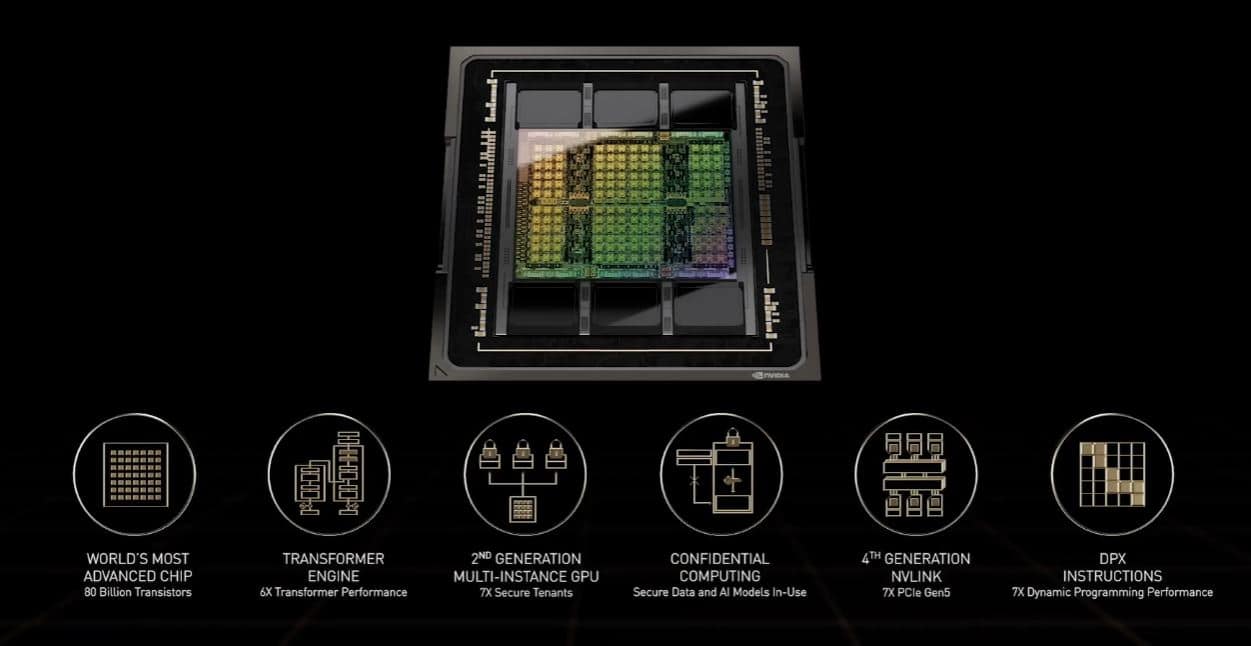
Au niveau de la disponibilité, les systèmes NVIDIA DGX H100, les POD DGX et les SuperPOD DGX seront disponibles auprès des partenaires mondiaux de NVIDIA à partir du troisième trimestre.
Les clients peuvent également choisir de déployer des systèmes DGX dans des installations de colocation exploitées par des partenaires de centres de données NVIDIA DGX-Ready, notamment les centres de données Cyxtera, Digital Realty et Equinix IBX.
Vous pouvez revisionner l’évènement dans son intégralité dans la vidéo ci-dessous.






