












Architecture Ampere
L’architecture Ampere représente la deuxième génération de cartes graphiques RTX. Celle-ci améliore de l’ordre de 1,9 fois les performances par Watts comparativement à l’architecture précédente Turing. Voyons plus en détail comment cela a été réalisé. Nous avons un GPU GA200 de chez Samsung avec une finesse de gravure de 8 nm et qui intègre 17,4 milliards de transistors. Nous avons un TDP de 200 W et l’alimentation se fait en 12-pins. Mais avant de partir dans les détails, refaisons le point sur les caractéristiques de cette RTX 3060 Ti face à une RTX 2060 SUPER, et en bonus on laisse les RTX 3070 et 3080 dans le tableau.
| RTX 3080 | RTX 3070 | RTX 3060 Ti | RTX 2060 SUPER | |
|---|---|---|---|---|
| GPU | 8nm GA102-200 | 8nm GA104-300 | 8nm GA200 | 12nm TU106-410 |
| Die Size |
628 mm²
|
392 mm² |
392 mm²
|
445 mm²
|
| Transistors | 28 B | 17.4 B |
17.4 B
|
10.8 B
|
| Board | PG132 SKU 10 | PG142 SKU 10 | PG190 | PG150 |
| CUDA Cores | 8 704 | 5 888 |
4 864
|
2 176
|
| Tensor Cores | 272 (4 par SM) 3è génération | 184 (4 par SM) 3è génération |
152 (4 par SM) 3è génération
|
272 2è génération
|
| RT Cores |
68
|
46 |
38
|
34
|
| Base Clock | 1440 MHz | 1500 MHz |
1410 MHz
|
1470 MHz
|
| Boost Clock | 1710 MHz | 1725 MHz |
1665 MHz
|
1650 MHz
|
| Shader Perf. | 29.8 TFLOPS | 20.3 TFLOPS |
16 TFLOPS
|
7.2 TFLOPS
|
| RT Perf. | 283 TFLOPS | 163 TFLOPS |
32 TFLOPS
|
21.7 TFLOPS
|
| Memory | 10 Go GDDR6X |
8 Go GDDR6
|
8 Go GDDR6
|
8 Go GDDR6
|
| Memory Clock |
19 Gbps
|
14 Gbps |
14 Gbps
|
14 Gbps
|
| Memory Bus | 320-bit | 256-bit |
256-bit
|
256-bit
|
| Bandwidth | 760 GB/s | 441 GB/s |
448 GB/s
|
448 GB/s
|
| TDP | 320W | 220W |
200W
|
175W
|
| MSRP | 719 euros | 519 euros |
419 euros
|
429 euros
|
Processeur de Streaming
L’un des aspects les plus importants de l’architecture Ampere repose sur les processeurs de streaming, alias les SM (streaming multiprocessors). Comparativement à la génération précédente, alias Turing, les nouveaux SM offrent le double les performances en FP32. D’ailleurs, sur cette RTX 3060 Ti on trouve 38 SM contenant chacun 4 Tensor Cores. On obtient donc les 152 Tensor Cores. Sur le schéma ci-dessous on peut voir de quoi est constitué un SM. On y voit les 4 Tensor Cores, mais également que chaque unité dispose de 32 cœurs FP32 ((32*4)*38) = les 4 864 cœurs CUDA. Notez que parmi les 32 cœurs présents dans chacune des quatre unités que compose un SM, 16 d’entre eux peuvent effectuer simultanément des calculs INT32 et FP32.
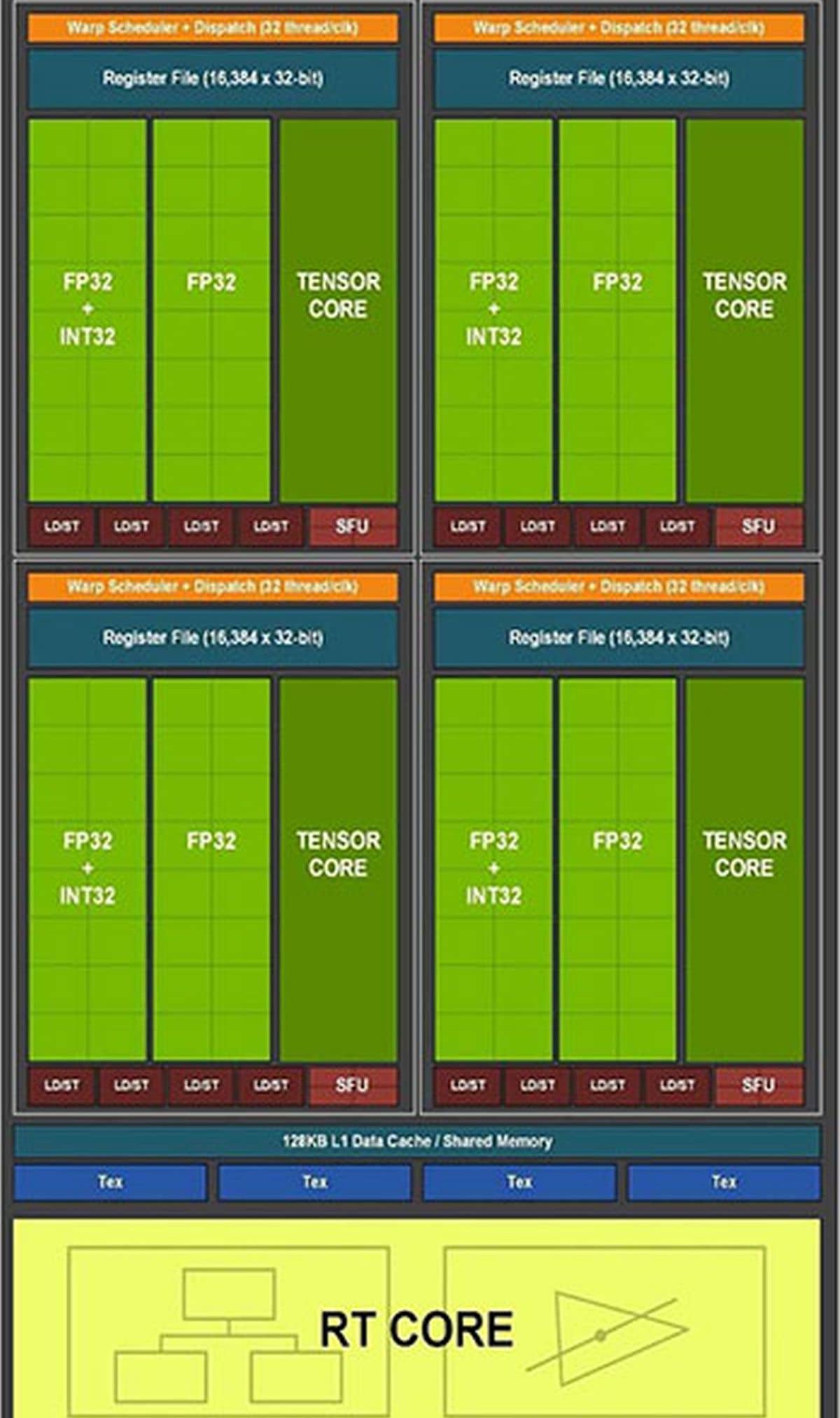
RT Cores et Tensor Cores
Il faut tout d’abord noter que le nombre de RT Cores augmente face à la RTX 2060 SUPER puisqu’on passe de 34 à 38, c’est peu, mais ce n’est pas la seule chose à prendre en compte. En effet, il faut aussi prendre en compte que l’IPC a augmenté de 1,7 fois. La technologie Ray Tracing utilise tout particulièrement ces cœurs. Pour rappel, cette technologie qu’on appelle aussi souvent « RTX » consiste à traiter la lumière en temps réel dans les jeux pour apporter davantage de réalisme dans les ombres, reflets, etc. On en parle bien plus en détail dans notre test détaillé sur Minecraft RTX. Ce réalisme atteint un niveau impossible à égaler manuellement. Le contrecoup de cette technologie est sa très forte consommation en ressources graphiques et la chute inévitable des FPS.
Pour pallier à cela, les Tensor Cores entrent en jeu avec la technologie DLSS (Deep Learning Super Sampling) qui repose sur un réseau neuronal d’apprentissage et augmente les FPS. Cette technologie fonctionne via un algorithme d’Intelligence Artificielle qui conserve, voire même améliore, la qualité d’image dans certains cas comme nous l’avons déjà constaté. Ces Tensor Cores sont issus de la troisième génération et bénéficient d’un IPC 2,7 fois plus important comparativement à la génération précédente. C’est aussi cette technologie qui permet, entre autres, de jouer jusqu’en 8K avec une RTX 3090 via un mode Ultra Performance.
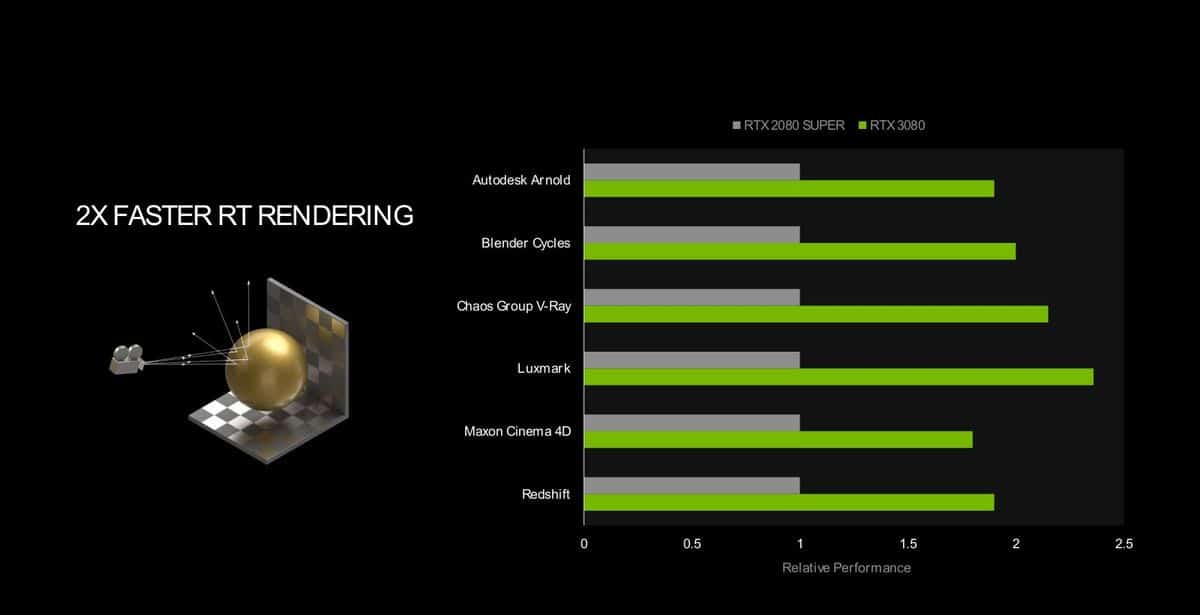
RTX IO
RTX IO est une nouvelle architecture de stockage. Concrètement, jusqu’à présent la carte graphique communiquait avec le stockage via le processeur et la mémoire système. Cette charge étant de plus en plus forte sur le processeur ; il peut y avoir un impact visible sur les performances, NVIDIA arrange la situation en faisant communiquer la carte graphique directement avec le stockage, sans intermédiaire, ce qui permet d’accélérer les débits. RTX IO apporte une décompression de données sans perte accélérée par GPU, ce qui signifie que les données restent compressées et regroupées avec moins d’en-têtes d’E/S, car elles sont déplacées du disque vers le GPU. NVIDIA annonce que cela permet de saturer la bande passante du PCIe 4.0 en atteignant le cap de 14 Go/s. À titre de comparaison, le système présenté sur la console de salon PlayStation 5 qui a fait beaucoup de bruit est à 9 Go/s.
À noter que cette technologie est annoncée comme compatible avec les cartes graphiques basées sur Turing également (RTX 2000 Series). Cela se fera via de prochaines mises à jour. Il faut aussi prendre en compte qu’un SSD PCIe 4.0 n’est pas obligatoire pour profiter de RTX IO. En effet, cela fonctionnera même avec un SSD NVMe en PCIe 3.0 cela fonctionne, il faut simplement se dire que plus le SSD sera rapide, plus les débits seront élevés et les temps de chargement courts dans les jeux.
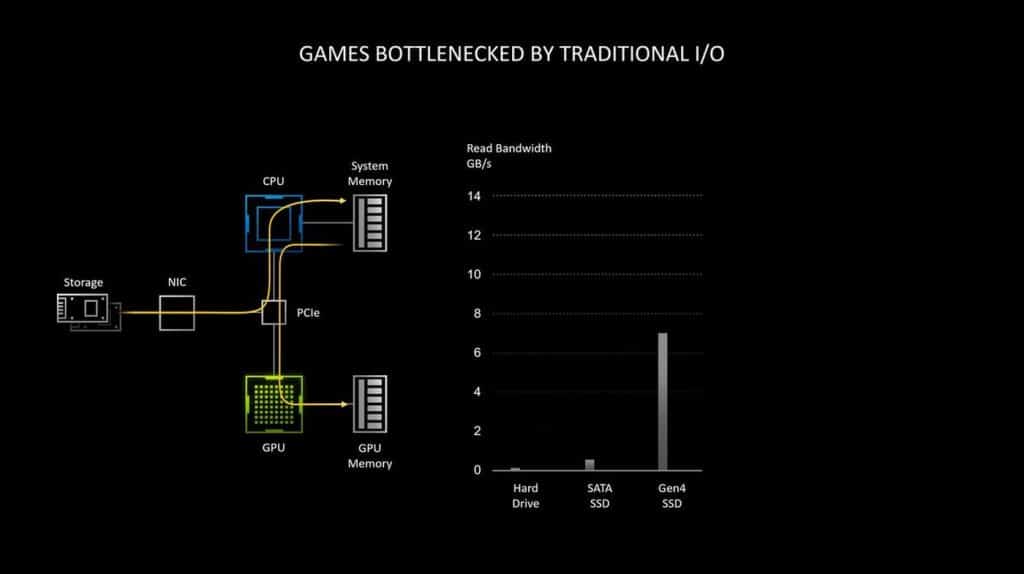
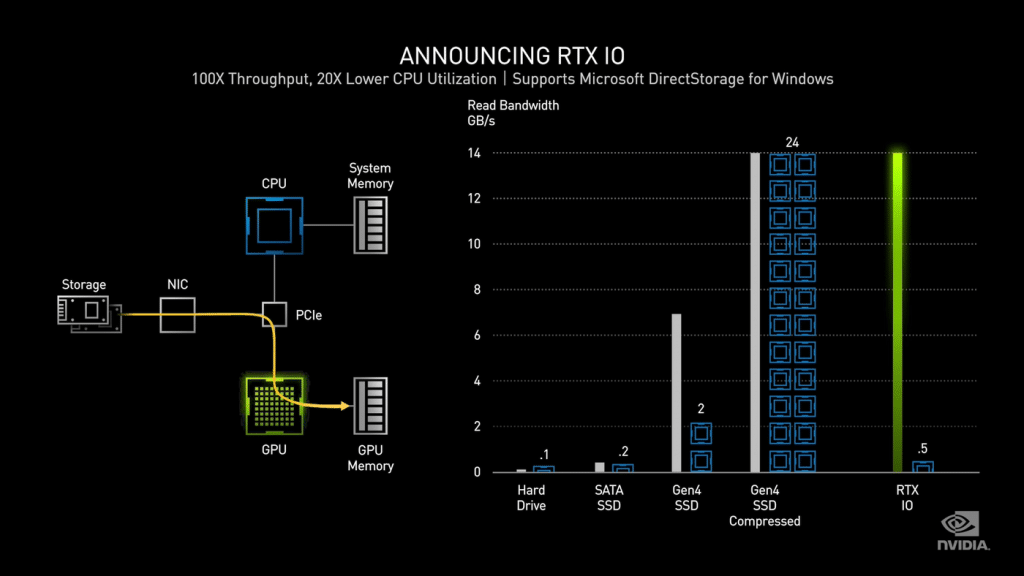
Selon les tests de NVIDIA, la lecture de données non compressées à partir d’un SSD à 7 Go/s comme le Samsung 980 Pro, nécessite l’utilisation complète de deux cœurs de processeur. Puis le système d’exploitation répartit cette charge de travail entre les cœurs et threads disponibles. Le problème est que pour un jeu triple A récent, des centaines de milliers de ressources individuelles sont entassées dans des fichiers compressés.
Bien qu’au niveau d’E/S du disque, les uns et les zéros soient toujours déplacés jusqu’à 7 Go/s, le flux de données décompressé au niveau du processeur peut atteindre 14 Go/s dans le meilleur des cas. Ajoutez à cela le fait que chaque demande d’E/S arrive avec sa propre surcharge : un ensemble d’instructions permettant au CPU de récupérer « x » éléments de ressource du fichier « y » et le livrer au tampon « z », le tout avec des instructions pour décompresser ou décrypter la ressource. Cela pourrait prendre énormément de puissance au processeur à une échelle de débit IO élevée, et NVIDIA fixe le nombre de cœurs de processeur requis à 24. C’est l’API DirectStorage qui permet aux périphériques de traiter directement la pile de stockage pour accéder aux ressources dont ils ont besoin. Notez aussi que l‘API de Microsoft a été initialement développée pour la Xbox Series X, mais elle fait maintenant ses débuts sur la plate-forme PC. Cela veut dire en revanche que les jeux doivent être optimisés pour cet API. Si on prend en compte le fait que cette technologie est déjà utilisée sur Xbox, alors les jeux console déjà portés sur PC disposent eux aussi de quelques optimisations pour l’API. Ils devront cependant recevoir quelques modifications pour être pleinement supportés sur PC.
Pour les cartes graphiques, on s’attend à ce que seules les RTX le supportent, y compris la génération précédente reposant sur Turing.
NVIDIA Reflex et Latency Analyzer
Durant l’annonce de cette génération de GPU, NVIDIA a également présenté la technologie Reflex. Celle-ci permet de réduire la latence des jeux (esports notamment) jusqu’à 50 %. Les premiers jeux prenant en charge NVIDIA Reflex sont : Valorant, Apex Legends, Call of Duty Warzone, Destiny 2 et bien sûr Fortnite. Les développeurs disposent d’APIs fournies par NVIDIA pour l’intégrer à leurs jeux. Du côté des utilisateurs cette technologie arrivera sous la forme d’une mise à jour du pilote GeForce. Notez que cela fonctionne non seulement avec les nouvelles RTX 3000 Series, mais également à partir des GTX 900, un aspect important à souligner. Pour rappel, la latence représente le laps de temps entre l’action, par exemple un clic sur la souris et le moment où l’action est affichée à l’écran.
Niveau fonctionnement, le pilote travaille de concert avec le moteur du jeu pour optimiser les débits du rendu 3D. La file d’attente de rendu est réduite dynamiquement et moins d’images sont laissées en file d’attente. NVIDIA déclare que cette technologie permet de garder le GPU parfaitement synchronisé avec le CPU (file d’attente de rendu 1: 1).
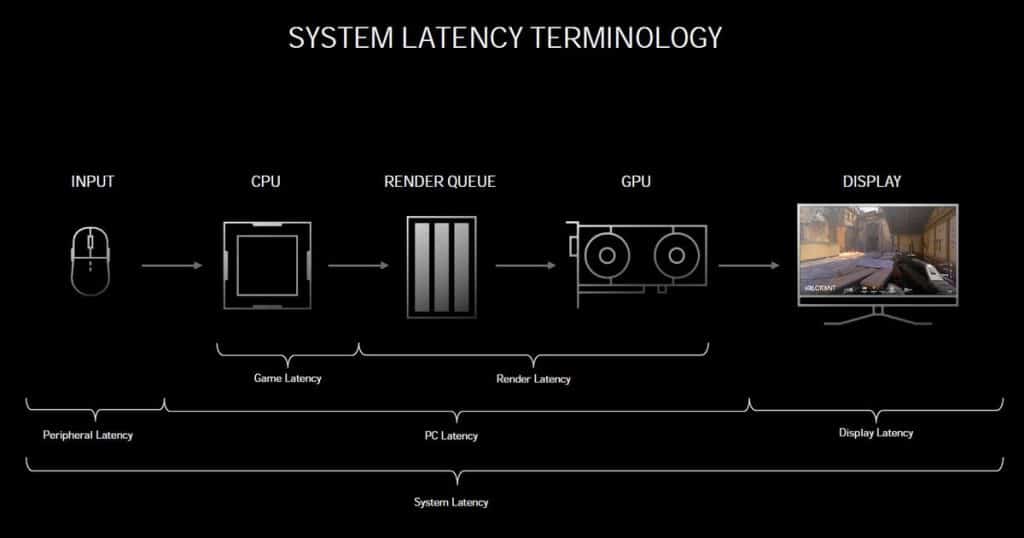
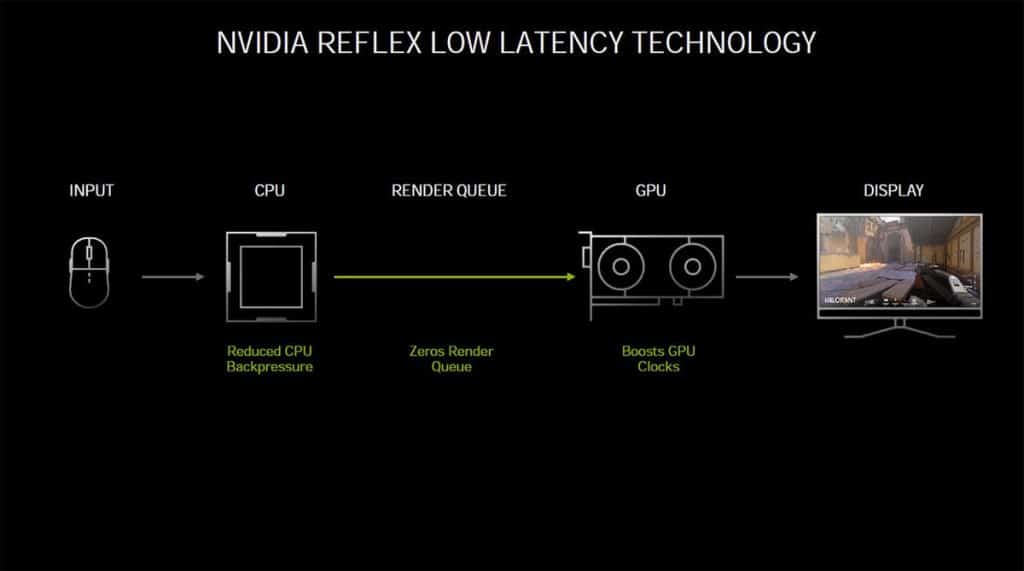
Sur le graphique ci-dessous, NVIDIA montre l’efficacité de sa technologie Reflex. Notez que sur la configuration de test il s’agit seulement d’une GTX 1660 SUPER avec un processeur Intel Core i9, le tout avec une définition 1080p. Dans les quatre jeux présentés, tous en profitent à plus ou moins grande échelle.

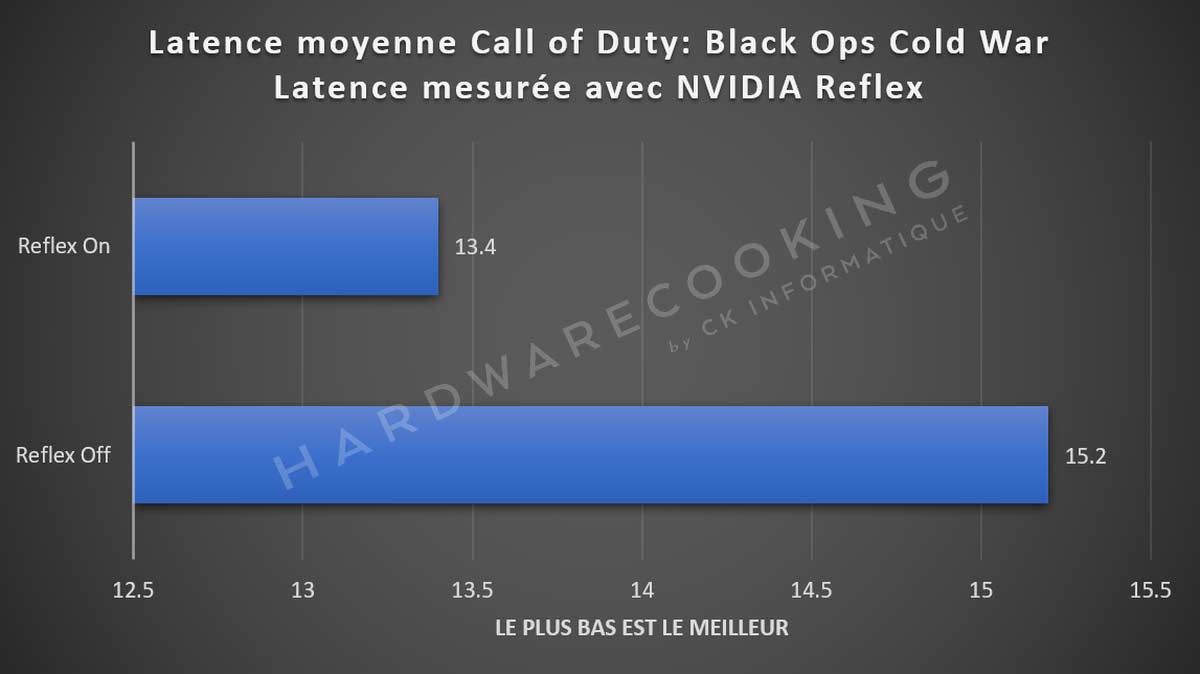
Pour tester cette fonctionnalité avec notre RTX 3060 Ti, nous sommes allés sur le dernier Call of Duty: Black Ops Cold War. Dans notre scène test, nous relevons 15,2 ms de latence sans la technologie NVIDIA Reflex et 13,4 ms avec la technologie activée.
Avec NVIDIA Reflex, la marque a présenté un nouveau standard pour les moniteurs esports : les écrans G-Sync 360 Hz avec la technologie NVIDIA Reflex Latency Analyzer. Cette dernière est intégrée via le module G-Sync de l’écran et permet de mesurer la latence d’un écran, d’une souris et du PC dans un jeu. Accompagnés d’un taux de rafraîchissement à 360 Hz qui réduit déjà naturellement l’input lag, ces écrans garantissent une latence particulièrement basse, idéale pour les jeux esports. De plus, cette prouesse ne repose pas sur des dalles de types TN qui sont généralement les plus rapides, mais sur des dalles de types IPS qui ont un bien meilleur rendu des couleurs.
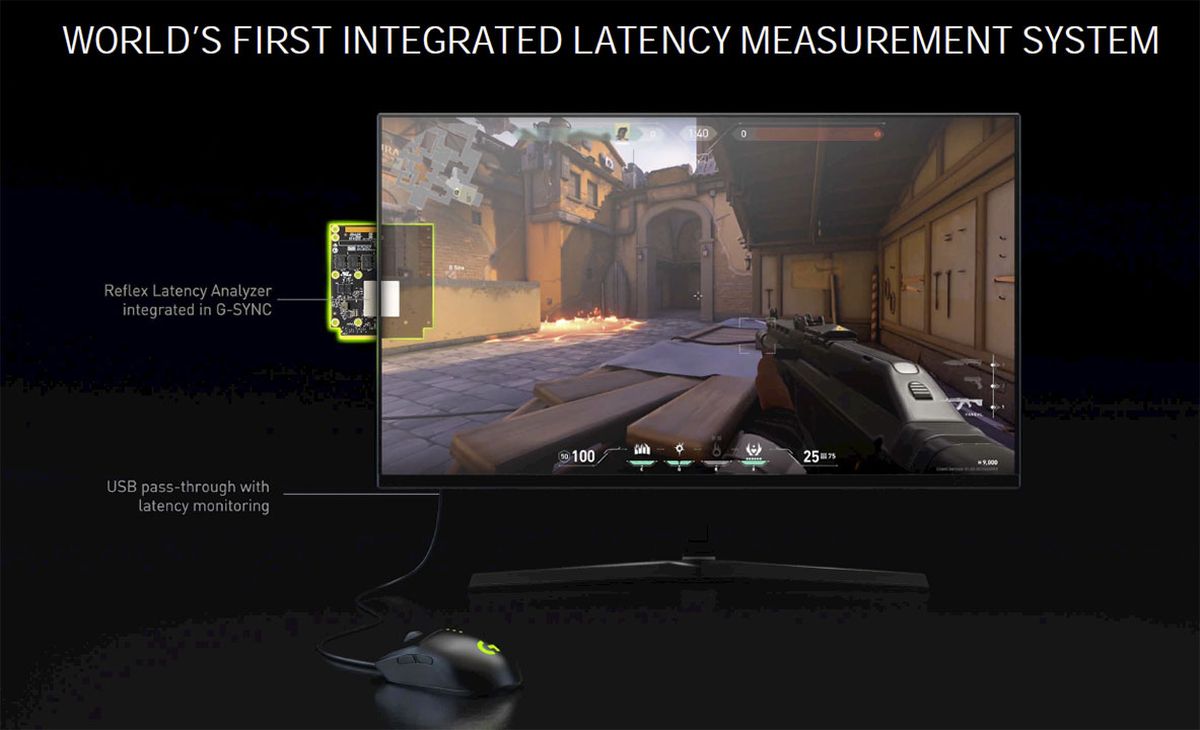
Sur les écrans G-Sync 360 Hz se trouve un HUB équipé de deux ports USB. On peut y brancher n’importe quel périphérique, mais c’est aussi là qu’il faudra brancher la souris certifiée NVIDIA pour profiter des fonctionnalités supplémentaires. Une fois branchée, la fonctionnalité s’activera depuis l’OSD de l’écran et à chaque action de la souris sa latence sera mesurée et affichée. De même, la latence du système complet est mesurée. Ci-dessous notre test dédié à la technologie NVIDIA Reflex Latency Analyzer.
Test : ASUS ROG Swift PG259QNR et NVIDIA Reflex Latency Analyzer
Passons à la suite et commençons avec les benchmarks sous 3DMark et compagnies.
Lire la suite
- Introduction et caractéristiques techniques
- Architecture Ampere, NVIDIA Broadcast et Reflex
- Overclocking, 3DMark et Furmark
- Rendus 3D
- Far Cry 5 et Assassins Creed Origins
- Watch Dogs: Legion et Call of Duty: Black Ops Cold War
- Control et Fortnite
- Deliver us the Moon et Red Dead Redemption II
- Doom Eternal et Wolfenstein
- Grand Theft Auto V
- Températures, consommation, performances par Watts et latence
- Conclusion
- Shooting photo complet




[…] HardwareCooking […]
Avant tout, merci pour le travail effectué sur ce site.
Je vois que la carte est comparé à une AORUS 3080 Xtreme
Un test de cette carte est prévu prochainement ?
Merci ! Oui, c’est en cours d’écriture 🙂